Original Published on PatternFly Medium Publication

If you’re a developer who loves hands-on tactical tutorials, then read on. Today, we’re covering Blorc.PatternFly.
First off, the basics: What is Blorc.PatternFly? Standing for Blazor, Orc, and PatternFly, Blorc.PatternFly is a library with the ultimate goal of wrapping all PatternFly components and making them available as Blazor components.
Now let’s jump into a tutorial. Keep in mind that this tutorial isn’t meant as an overview of Blazor — you’ll need some basic knowledge of Blazor before diving in.
You’ll also need to have these tools handy:
- Visual Studio 2019 (16.4.2)
- Blazor (3.1.0-preview4.19579.2)
Step 1: Creating the project
First, go through the Get started with ASP.NET Core Blazor tutorial for Blazor WebAssembly experience. You’ll create the Blazor project in this tutorial, and you’ll only have to convert the Bootstrap to PatternFly. For the purpose of this guide, use Blorc.PatternFly.QuickStart as the project name.
Follow the on-screen instructions of the Visual Studio project:
Create a new project.
Configure your new project.
Create a new Blazor app with Blazor WebAssembly experience.
The Blazor template is built on top of Bootstrap. So the resulting app looks like this:
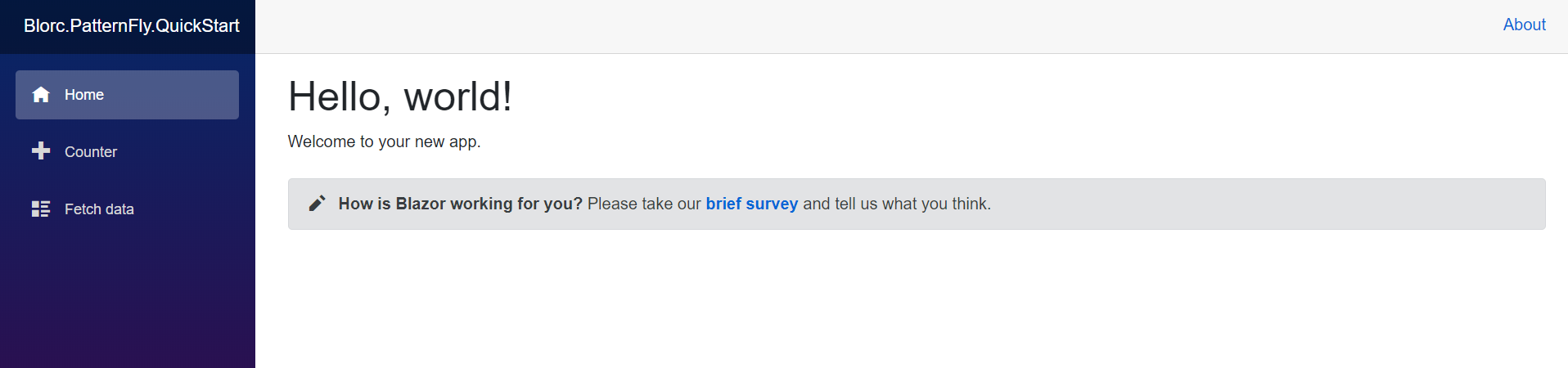 |
| Index.razor and SurveyPrompt.razor |
 |
| Counter.razor |
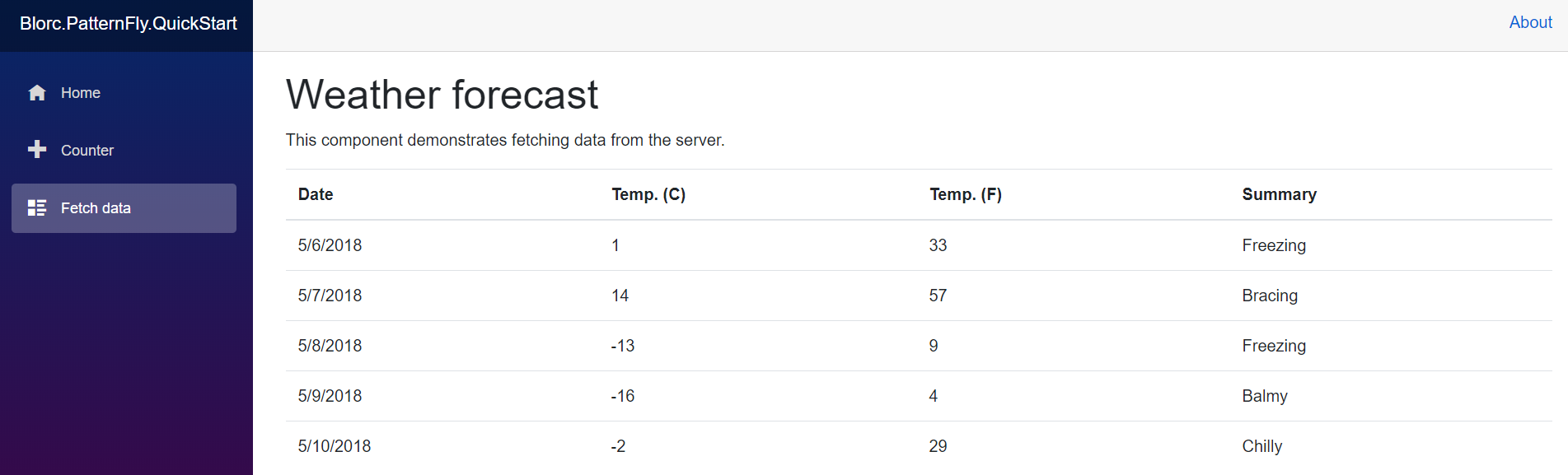 |
| FetchData.razor |
Step 2: Startup configuration
Once the project has been created, add Blorc.PatternFly as a package reference via NuGet. At the time of writing this article (which I hope you’re enjoying!), this package is only available as prerelease. To install the latest prerelease version, check the Include prerelease option in the Package Manager.
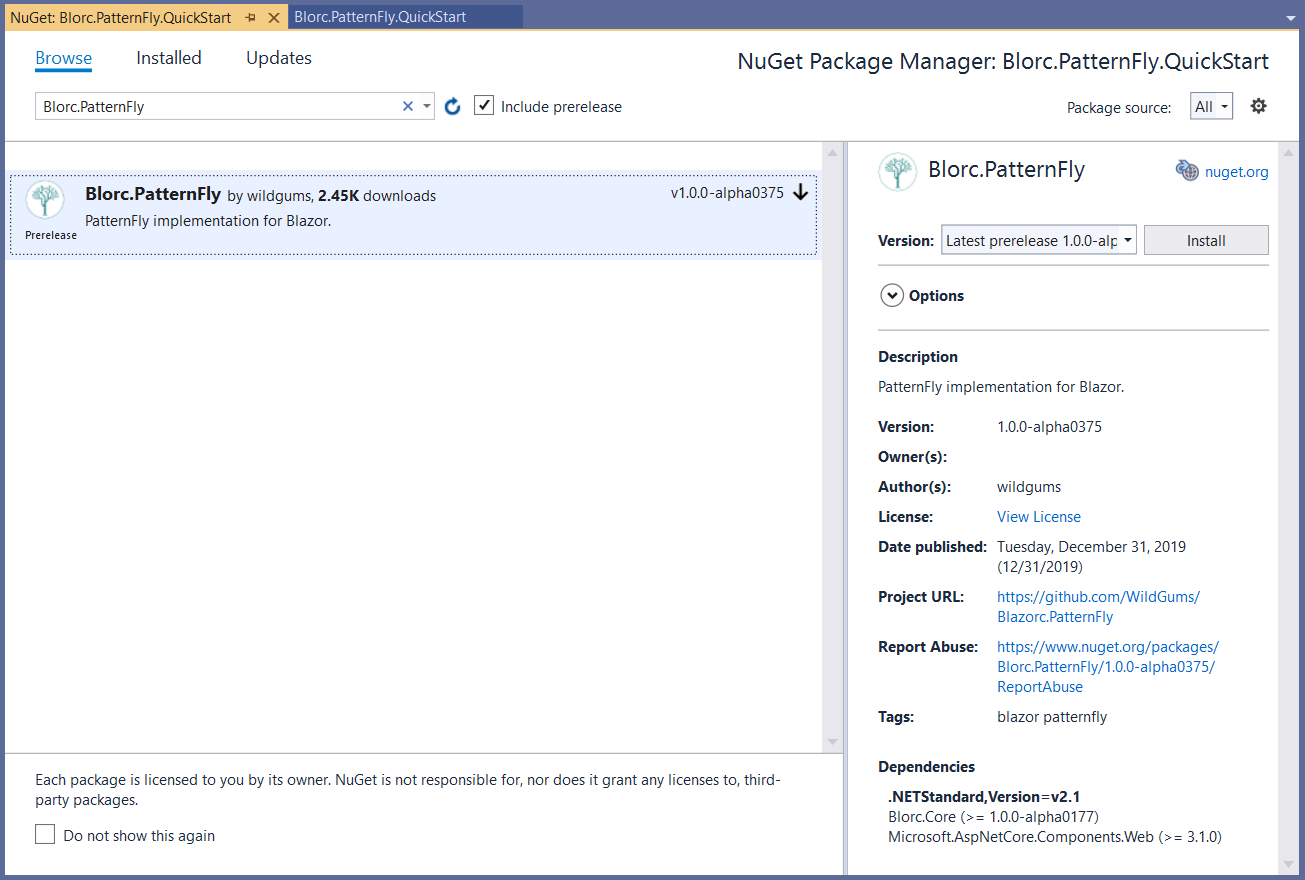 |
| Adding latest prerelease of Blorc.PatternFly package |
Also, it’s mandatory to register the Blorc.Core services in the ConfigureServices method of the Startup class, shown below:
Once the Blorc services are registered, it’s time to start replacing the UI elements, starting with the content of the index.html and site.css files.
To make sure that no unused dependencies are being deployed, remove the bootstrap and open-iconic directories from the wwwroot/css directory.
You can do this yourself by following the steps below or you can clone the repository with the source code of this tutorial.
For instance, the MainLayout component must inherit from PatternFlyLayoutComponentBase, and you can use the Page component as follows:
For the NavMenu, you could use the Navigation component and update the razor file as shown below:
Finally, update the content of the Counter and FetchData pages.
And that’s it! Great work. Your application should now look like the screenshots below:
If you would like support for any new component, contribute to the Blorc.PatternFly library on GitHub. You can get in touch by:
Finally, if you want to see the latest develop branch of Blorc.PatternFly in action, you can browse to the live demo with a full overview of all the PatternFly components already available for Blazor. And you’ll probably agree: PatternFly and Blazor are awesome — and combined, they are a beautiful pair.
Interested in contributing an article to the PatternFly Medium publication? Great! Submit your topic idea, and we’ll be in touch.
Step 3: Updating pages and components
The time has come to update the components. You should be able to update the content of the razor files with references to the available Blorc.PatternFly components.You can do this yourself by following the steps below or you can clone the repository with the source code of this tutorial.
For instance, the MainLayout component must inherit from PatternFlyLayoutComponentBase, and you can use the Page component as follows:
For the NavMenu, you could use the Navigation component and update the razor file as shown below:
Finally, update the content of the Counter and FetchData pages.
And that’s it! Great work. Your application should now look like the screenshots below:
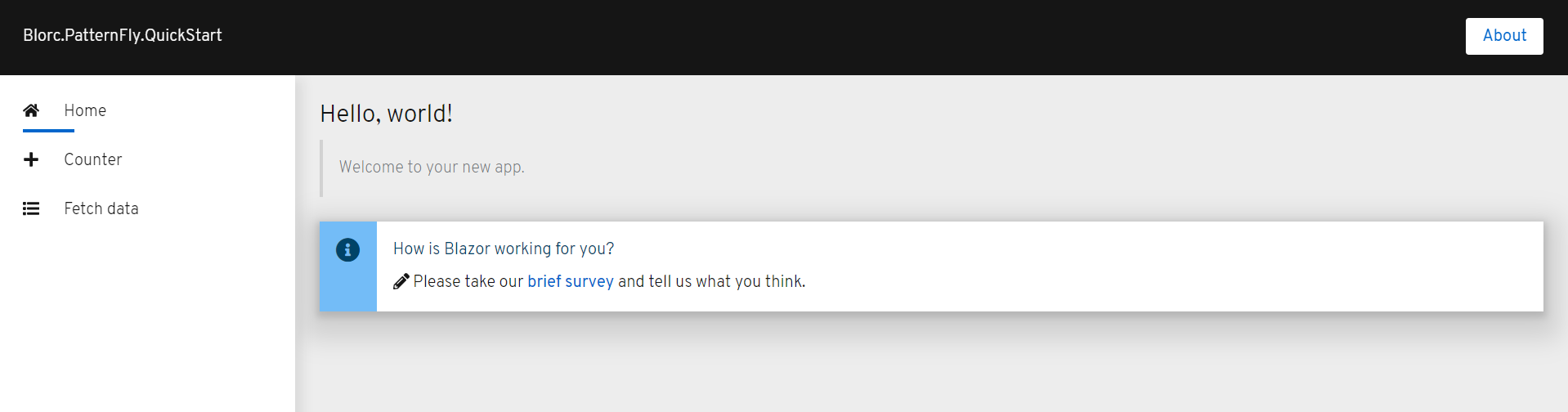 |
| Index.razor and SurveyPrompt.razor |
 |
| Counter.razor |
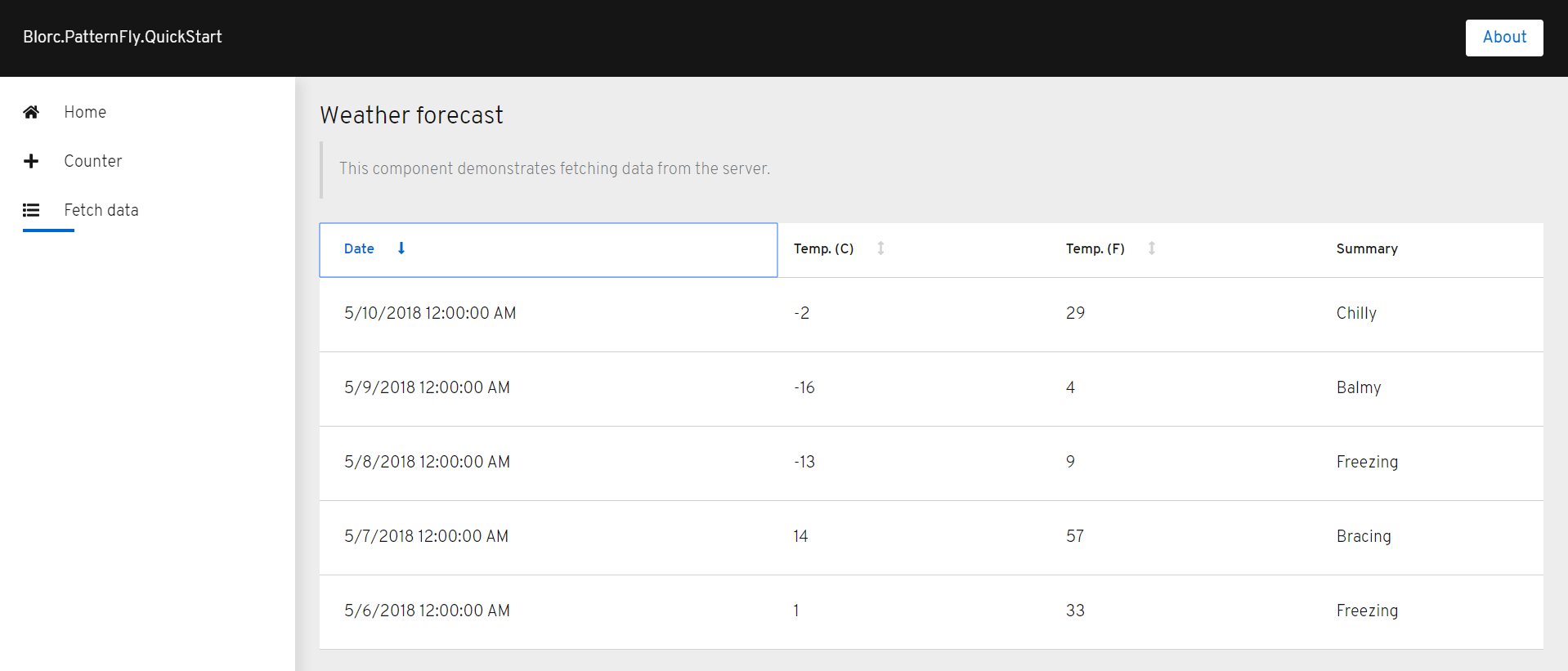 |
| FetchData.razor |
Send us your feedback
Keep in mind that the library is a work in progress, and there are still a few PatternFly components being implemented. We are continuously releasing new versions. The good news is that Blorc.PatternFly is open source, and the sources are available on GitHub.If you would like support for any new component, contribute to the Blorc.PatternFly library on GitHub. You can get in touch by:
- Creating tickets.
- Contributing by pull requests.
- Contributing via Open Collective.
Finally, if you want to see the latest develop branch of Blorc.PatternFly in action, you can browse to the live demo with a full overview of all the PatternFly components already available for Blazor. And you’ll probably agree: PatternFly and Blazor are awesome — and combined, they are a beautiful pair.
Interested in contributing an article to the PatternFly Medium publication? Great! Submit your topic idea, and we’ll be in touch.




































