A few days ago, I introduced you StoneAssemblies.MassAuth as a Gatekeeper implementation.
Today, as promised, I bring you a hands-on lab that consists of the following steps:
- Set up the workspace
- Contract first
- Implementing rules
- Implementing services
- Hosting rules
- Build, run and test
So, let’s do this straightforward.
Prerequisites
Step 1: Set up the workspace
To set up the workspace, open a PowerShell console and run the following commands:
After executing these commands, StoneAssemblies.MassAuth.QuickStart.sln Visual Studio solution file is created, which includes the following projects:
- StoneAssemblies.MassAuth.QuickStart.Messages: Class library for messages specification.
- StoneAssemblies.MassAuth.QuickStart.Rules: Class library to implement rules for messages.
- StoneAssemblies.MassAuth.QuickStart.Services: Web API to host the services that require to be authorized by rules.
- StoneAssemblies.MassAuth.QuickStart.AuthServer: Authorization server to host the rules for messages.
The commands also add the required NuGet packages and project references.
If you review the content of the StoneAssemblies.MassAuth.QuickStart.AuthServer.csproj project file, you should notice a package reference to StoneAssemblies.Extensibility. This is required because all rules will be provisioned as plugins for the authorization server.
The extensibility system is NuGet based, so we need to set up the build to provision the rules and messages as NuGet packages. For that is the purpose, this workspace configuration includes two more files. The build.cake, a cake based build script to ensure the required package output,
and the tye.yaml that will help us to run and debug the solution.
Step 2: Contract first
Let's add a bit of complexity to the generated problem, related to the weather forecast. For instance, let's say we will allow requesting forecasts from a certain date, as some forecasts may not be available due to the complexity of the calculations.
For that purpose, we will add the following class to the message project, to request the weather forecast with the start date as an argument.
Step 3: Implementing rules
Now we are ready to implement some rules for such a message. Continuing with our scenario, let's say the forecast data is only available from today and up to 10 days. This operation could be more complex through a query to an external database, but for simplicity, it will be implemented as follows.
Step 4: Implementing services
It's time to complete the WeatherForecastController implementation in the service project. It should look like this.
Notice the usage of AuthorizeByRule attribute on the Get method, to indicate that the input message WeatherForecastRequestMessage must be processed and validated by the authorization engine before the method execution.
We also have to update the Startup class implementation.
Basically, the AddMassAuth service collection extension method is called to register the library services and also ensure communication through the message broker. Remember, StoneAssemblies.MassAuth is built on top of MassTransit. Finally, to read the configuration via environment variables we must update the Program class to this.
Step 5: Hosting rules
To host rules, we provide a production-ready of StoneAssemblies.MassAuth.Server as docker image available in DockerHub. But for debugging or even for customization purpose could be useful build your own rule host server. So, in the server project, we also have to update the Startup class implementation, to initialize the extensibility system and load rules.
Again, to read the configuration via environment variables the Program file must be updated like this.
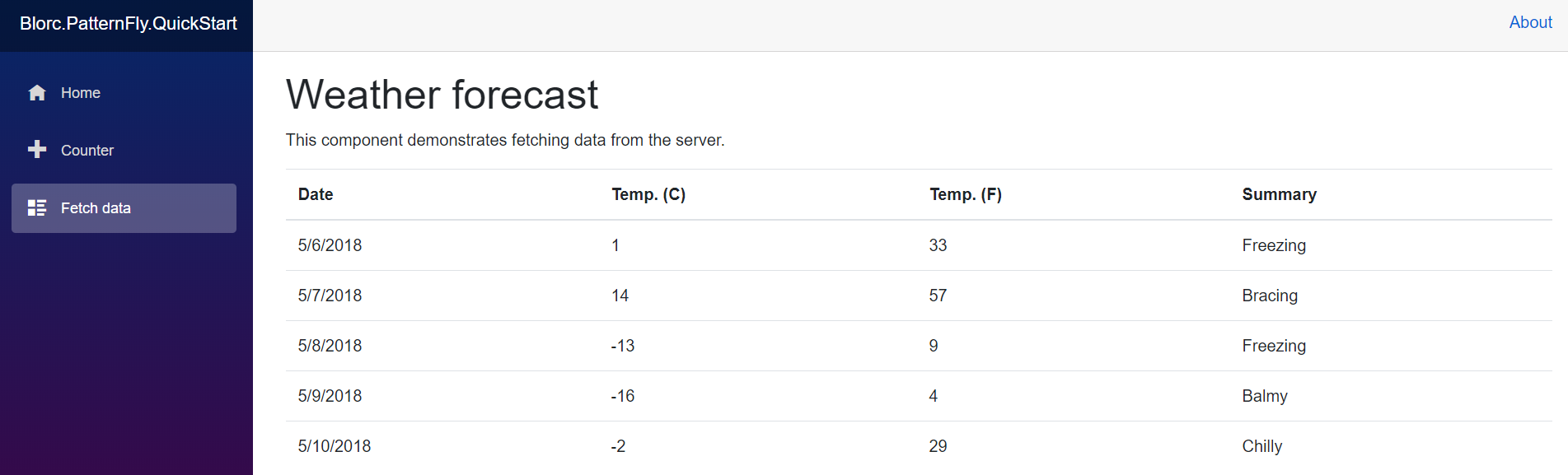
Step 6: Build, run and test
Let's see if this works. So, cross your fingers first ;)
To build and run the project, open a PowerShell terminal in the working directory and run the following commands.
Open your browser and navigate to http://localhost:8000 to display the Tye user interface.


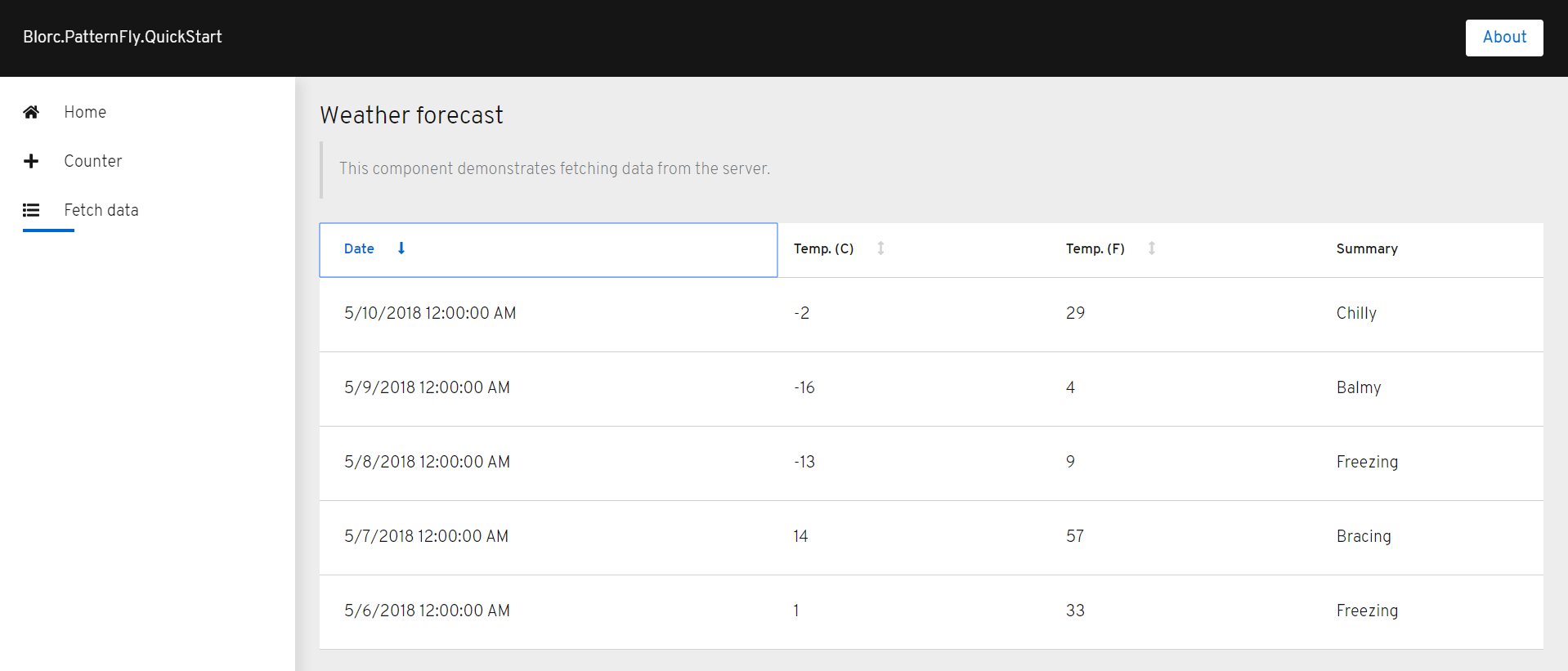
Let's do some weather forecast requests. For instance with a valid request
the output looks like this

but with an out of range request
the output shows an unauthorized response.

So, as expected, it works ;)
Closing
In case it doesn't work for you, you can always try to review the final and complete source code of this hands-on lab is in the StoneAssemblies.MassAuth.QuickStart repository is available on GitHub.
Remember StoneAssemblies.MassAuth is a work in progress, we are continuously releasing new versions, so your feedback is welcome. Also, remember that it is an open-source project, so you can contribute too.
Enjoy «authorizing» with pleasure and endless possibilities.