What is TuEnvio?
Described by CIMEX itself, TuEnvio is an “E-Commerce platform created by the CIMEX corporation for the national customer, which allows online purchases from the comfort of your home”.
But you may wonder: Why is this new? The fact is that the expansion of Internet access in Cuba is actually a new phenomenon. From almost zero, without infrastructure, in a couple of years, Internet access for many Cubans is almost a reality. Right, it is very expensive thanks to ETECSA, but it continues to expand, which is good.
Since Cubans had no internet access, “no one” worried about selling products online. At least, not for Cubans that live in Cuba. Therefore, they “invented” a service called EnviosCuba for foreign families could buy products for their national’s relatives. A kind of favor-based business model, which is very sad. An approach to only capture foreign currency instead also think in the prosperity and comfort of Cubans that live in Cuba.
But the SARS-Cov-2 arrived. They would be forced to launch a service on a scale for which they were neither technologically nor logistically prepared. Its name TuEnvio.

The new jungle
TuEnvio looked promising. Several instances of the store, distributed in some physical stores, showed its “stock” online. Users were able to navigate, search and buy. But somewhat was not right. Buying what you needed wasn't exactly that easy. Eventually, you could catch a thing but the stress began to increase. As a vigilante, to buy a high demanded product, you had to stay up late at night.
TuEnvio doesn't have a native notification system, so I started implementing something to help me stay tuned. I was at home (remember COVID19), I was bored, but most importantly I had to buy.
That was the birth of YourShipping.Monitor as a project.

@cimex_cuba #TuEnvio #Telegram #Bot #Demo 😉
— Alexánder Fernández (@alexfdezsaucoCU) May 31, 2020
/search agua pic.twitter.com/3fTR2z3hIp
So, the idea was to create an application similar to CamelCamelCamel with target TuEnvio. But everything would change when The new jungle arises.
Shoot first, ask later
The best description of the situation was published in this video. A "parodied" scene from The Big Bang Theory television series. By the way, to understand what is happening you need to read the subtitles in Spanish ;). I'm not sure who the original author is. But it rocks. If you know him, please just let me know to update this post.
It turns out that shopping at TuEnvio wasn't too easy. Only a few viewed the products because they accessed them at the right time. Links leak?
On the other hand, the workload generated by the simultaneous access of thousands of people was handled by DATACIMEX's developers with an incorrect caching approach. If someone doesn't see a product at the right time, should wait for the cache to be invalidated within the next 3 minutes.
This, combined with the limited offer, meaning that the majority of TuEnvio's users were unable to purchase a thing. Worse still, they didn't even see a single product.
Under these circumstances YourShipping.Monitor's goals changed. I needed the notifications. But actually, I needed to interact with the store in light speed mode to add products to the shopping cart.
I almost forget that this is also a technical post. So, here we go.
Parallel web scraping
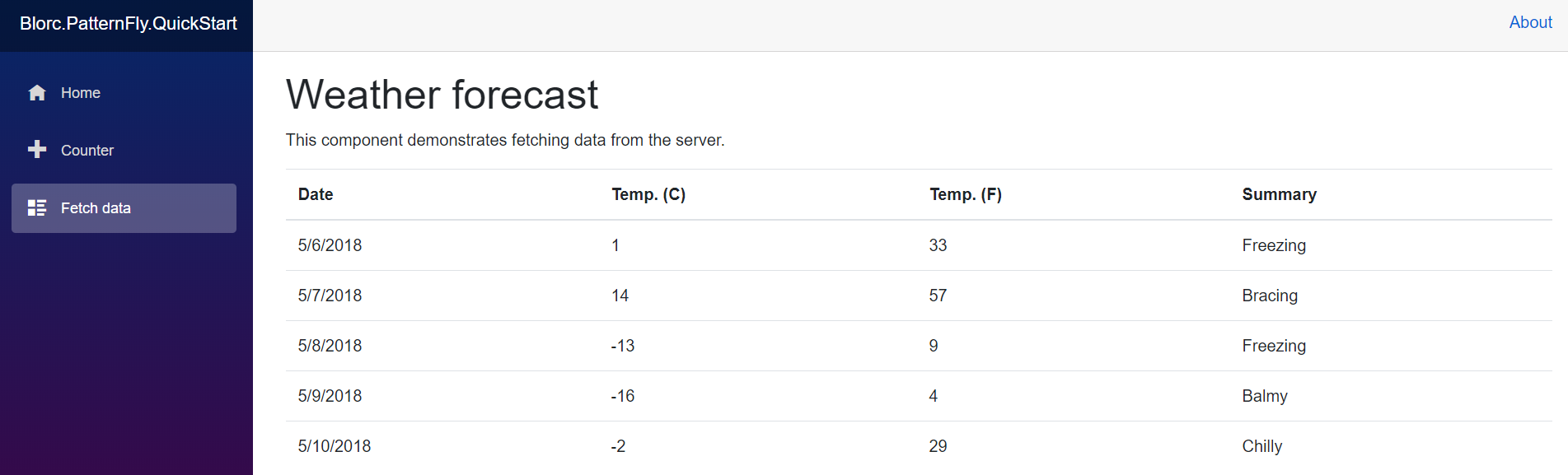
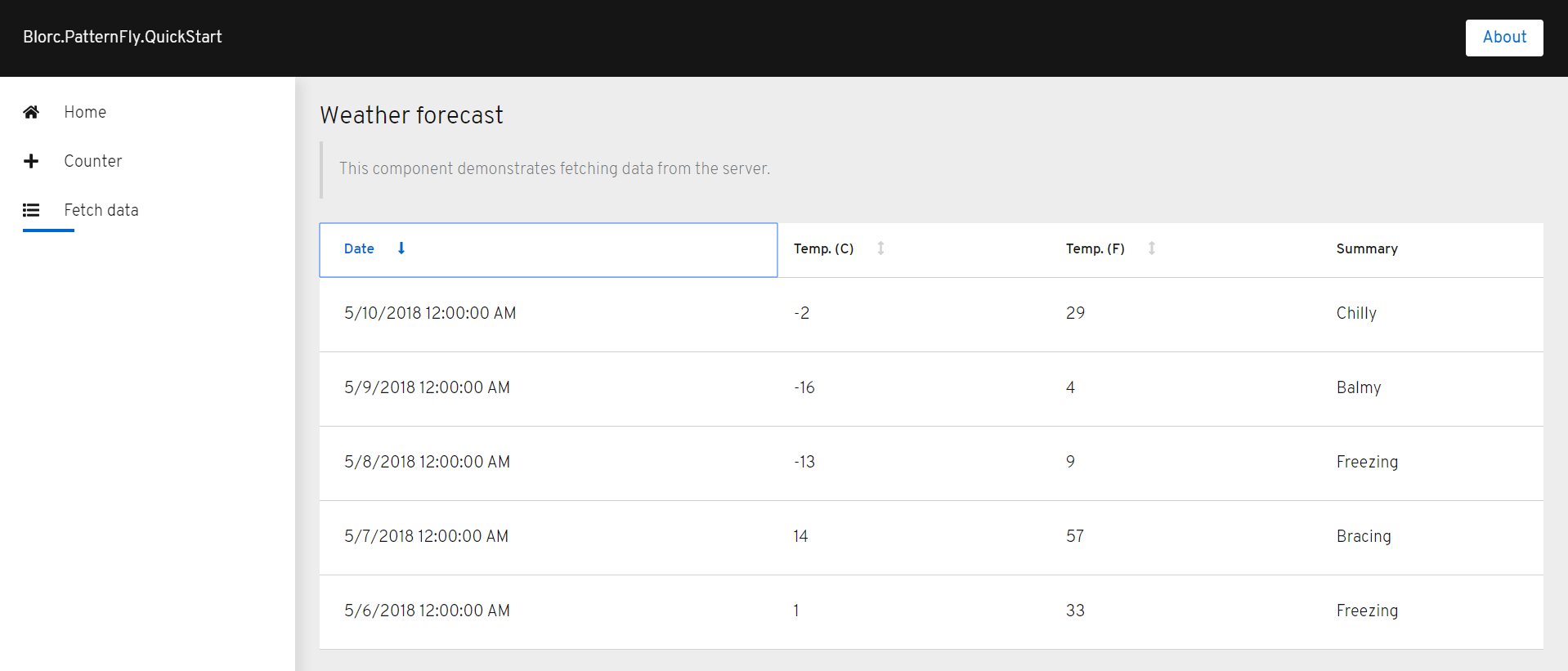
YourShipping.Monitor is being implemented using the NetCore full stack including the frontend with Blazor. It allows me to track stores, departments, and products from its uniform resource locator (URL). The user must enter the link and a background process extracts the information and also tries to interact with the options of the store with a single rule: add a product to the cart at first sight.
But what if I'm looking to the wrong department? What if one product is available in the very same second as another. This is why it was important to send as many requests as possible at the same time. Using the asynchronous capabilities of C# in combination with AsyncEnumerable library, I was able to do it, just like this.
But it wasn't just me. A community of Cuban developers launched several applications to help people to buy. Even when such applications required user interaction, the workload affected the store's servers a lot. So, CIMEX responded with an anti-scraping approach.
Fighting against the anti-scraping system
One day the scraper stopped working. All requests were redirected to a page to execute this JavaScript code.
It could be easy to figure out what is happening. They expect a cookie, with a value generated in that JavaScript. I'm already using AngleSharp to explore the DOM elements. It might be possible to evaluate such a function, to acquire the value of the cookie, using the same library? The answer is yes. AngleSharp.Js is an experimental extension that allows you to run simple JavaScript functions. So, after capturing the parameters with regex, I was able to call the function to capture the cookie value as well.
It could be easy to figure out what is happening. They expect a cookie, with a value generated in that JavaScript. I'm already using AngleSharp to explore the DOM elements. It might be possible to evaluate such a function, to acquire the value of the cookie, using the same library? The answer is yes. AngleSharp.Js is an experimental extension that allows you to run simple JavaScript functions. So, after capturing the parameters with regex, I was able to call the function to capture the cookie value as well.
Moving to unattended mode
At this point, I was creating the session with the browser, saving the cookies.txt file, and making it available to the scraping server (a.k.a. YourShipping.Monitor.Server). The main reason, the captcha. But TuEnvio's captcha looks like this.

Actually, it doesn't look like a very hard captcha. Nothing that has not been broken before with tesseract-ocr. So, just added the reference to a .NET wrapper of tesseract and wrote down this
and you know what? It worked.
Final thoughts
I know, this doesn't seem a bit stressful, but yeah, now it is. With YourShipping.Monitor and a bit of luck, I have been able to capture something in TuEnvio's stores. There is no guarantee, so I always insist that ETECSA should not charge for access to virtual stores. Someone can spend more money trying to buy than buying.
Recently, CIMEX released the store's opening schedule. So now, with the effective combination of my command-line tool nauta-session, to manage Nauta Hogar sessions, I can already go to sleep, stressless 😉.
Me cuadró. Ya me puedo acostar a dormir 😉. pic.twitter.com/Xe1UwFYnPC
— Alexánder Fernández (@alexfdezsaucoCU) September 25, 2020